
Sing
idea by Rainbow_sjy, solution by zhoukangyang, Rainbow_sjy, data by skip2004, Rainbow_sjy
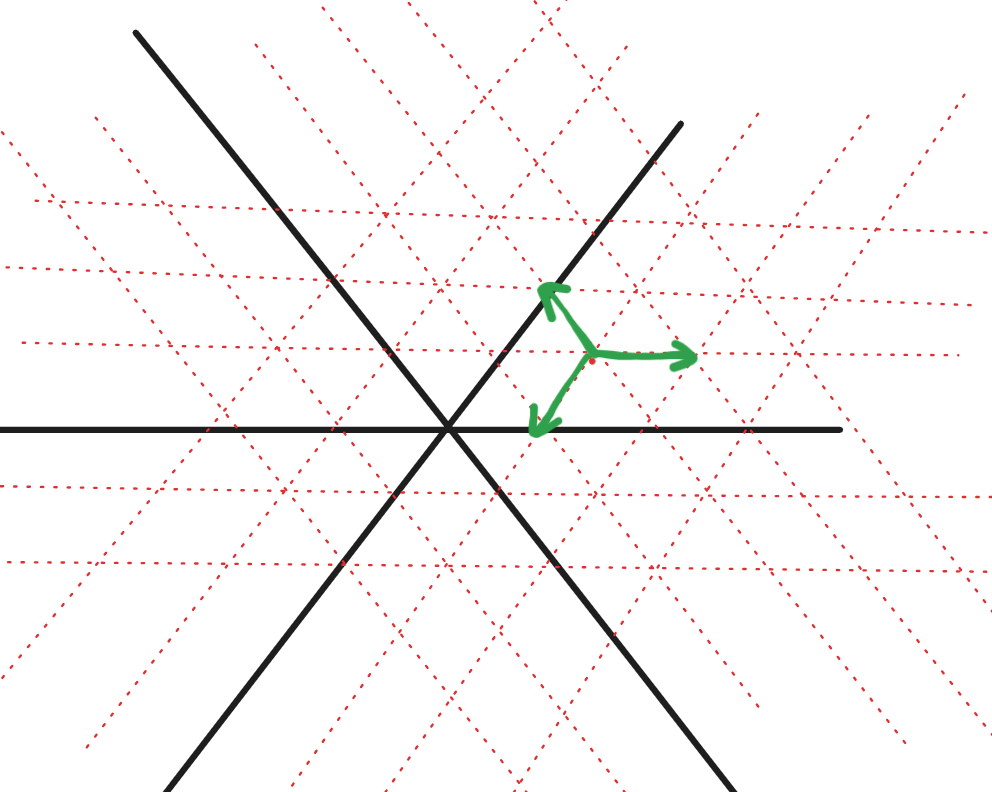
考虑如下性质:将 $(i,p_i)$ 画在坐标轴上,如果一个点向左上方($i$ 变小,$p_i$ 变大)的方向移动,则限制一定更紧。
据此,我们可以只考虑所有 $p_i$ 为前缀最大值和前缀次大值的限制。
考虑枚举 $p_1$ 填什么。
如果 $p_1\le k+1$,直接对后面毫无限制。
如果 $p_1 > k+1$,则要求 $p_2,p_3,\dots,p_{p_1-k-1}$ 都 $\le k+1$。只有 $p_1$ 是前缀最大值,后面这段数也对更后面毫无限制。于是可以递归到继续填 $p$ 的一个后缀。
分析清楚排列的结构后,就可以计数了:
对于 整个过程中,一个前缀中只能有一个 $p_i > k+i$ 的;如果钦定了 $p_i > k+i$,那么后面的一段的转移系数是固定的。大概长成这样:
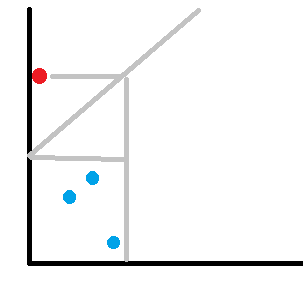
直接暴力 dp 是 $O(nk)$,观察到长度相等的转移系数相等,可以多项式求逆做到 $O(n\log n)$。
对于排列有限制位置的情况,和上述 $O(nk)$ 做法一样,注意一些细节。
希望市
idea by bulijiojiodibulido, solution by bulijiojiodibulido, zhoukangyang, std by zhoukangyang, Rainbow_sjy, chenxinyang2006, data by skip2004, chenxinyang2006
算法一
首先考虑如下算法:
维护 $n$ 个独立集,第 $i$ 个独立集只有 $i$ 号点。
每次将四个独立集合并为三个:
- 对于第一个独立集的每个点,考虑将其插入到剩下三个中的一个。
- 注意到每个点最多只会和两个其他点相邻,因此总是存在插入方法。
这样,我们每次可以用 $\mathcal O(n)$ 的代价将 $m$ 个独立集变为 $\frac{3m}{4}$ 个。
执行 $\mathcal O(\log n)$ 轮之后,总共就只会有 $C$ 个独立集($C\ge 3$)。
接下来,考虑问出这些独立集之间相互连的边。
考虑二分。首先定位出每个点连的边在哪些独立集中,然后进行二分,每次把每个独立集分成两份,然后再对每个点确定出它连的边在哪些分开来的独立集中。这样需要进行 $\log n$ 轮,每轮 $\mathcal O(n)$ 步。
这个算法总共消耗了 $\mathcal O(\log n)$ 轮和 $\mathcal O(n\log n)$ 步。
对于此类量级正确的算法,根据算法常数可以获得 $70\sim 100$ 分。
算法二
接下来,我们需要一些常数优化来通过此题。接下来我来说一下 std 中实现了的优化。
优化1: 最开始的时候可以从一些大独立集开始进行操作。我们对这些点建立线段树,询问所有线段树上的区间是否为独立集。为了减少移动步数,可以不遍历高层的点。
优化2: 找独立集之间的边时,可以只找出每个点连到它之前独立集的边,也就是对每条边在独立集位置较后的端点统计贡献。
优化3: 在剩下 $B_0$(可以取 $20$ 左右)个独立集的时候就停止合并,找到每个点连往哪些独立集,接着把每个独立集划分为 $B_i$ 份,然后再确认出每个点连往其中的哪些。此时已经有 $\sum B_i$ 个独立集了,一个点连向一个独立集连两条边的概率很低,因此对这部分点可以暴力;否则,对于一个点 $x$ 连一条边到独立集的情况,可以对这个独立集二进制分组:第 $p$ 组询问 $x$ 是否向第 $p$ 位为 $1$ 的点连边,这样就能单次交互解出编号了。这里的 $B_0$ 和 $B_i$ 可以自主调整。如果 $n$ 更大,还可以增加递归层数。
加上这些优化后,我们就能通过此题了。
这题应该还有很多做法,欢迎大家在评论区/博客区里分享自己的解法!
算法 $e$
在出题过程中,我们还发现了一些其他优化方法,但由于没时间写std了选手在赛场上难以实现过多优化,这些优化方法并没有体现在题目限制中。
单次交互问出独立集之间的连边
优化3中所描述的算法非常暴力,我们实际上可以通过一轮交互问出一个集合 $S$ 的点到一个独立集 $T$ 的所有边:固定一些 $T$ 的子集 $T_0,T_1,T_2,...,T_{k-1}$,对 $S$ 的每个点 $x$ 都问 $x$ 和 $T_i$ 中的哪些有连边。设 $u\in T$ 出现过的集合为 $f_u = \{i|u\in T_i\}$,那么假设 $x$ 连接了 $T$ 里内的 $u$ 和 $v$,我们就知道了 $f_u\cup f_v$。这可以看成是构造一个长度为 $2^k$ 的序列 $a_1,...,a_{|T|}$,要求对于所有 $i\leq j$,$a_i|a_j$ 互不相同。
我们可以通过一些随机化算法构造 $a$ 序列,比如这题就是一个要求构造 $a$ 序列的题目。但是这种算法至少有 $\mathcal O(|T|^2)$ 的时间复杂度,要求 $|T|$ 不能过大。
接下来我给出一个确定性构造:既然我们能够求出 $a_i|a_j$,那么我们可以把所有 $a$ 的位取反复制一遍,算出 $a_i\& a_j$,进而用 $(a_i|a_j)\oplus (a_i\& a_j)$ 算出 $a_i\oplus a_j$。此时我们可以用一个经典构造做到 $k=4 \lceil\log |T|\rceil$。
关于独立集合并的优化
考虑每次取一个 $k$,将 $k$ 个独立集合并为一个。我们可以假设合并完之的大小不超过 $\frac{n}{\log n}$,因为只有 $\log n$ 个独立集的时候就可以开始查询独立集之间的边了。
此时,如果我们合并了集合 $S_1,S_2,...,S_k$。对于每个点,其向其他独立集中有连边的概率约为 $\frac{|\sum S_i|}{n}\leq \frac{1}{\log n}$,这意味着大多数点都可以合并进入一个新的独立集。
对于其他相互连边的点(称为特殊点,不妨假设 $T_i$ 为 $S_i$ 中的特殊点),它们也形成一些独立集,我们可以用刚才所说的交互方法,一轮问出 $T_i$ 之间的所有连边,然后再将 $\cup T_i$ 分为两个独立集放回到独立集序列中。
我们还可以优化轮数上的常数:$\frac{\sum S_i}{n}$ 通常比 $\frac{1}{\log n}$ 小很多,因此我们还可以再将很多 $\cup T_i$ 分在一组。也就是说,我们问出 $r\times k$ 个独立集之间的所有边,然后再把这些点作为两个独立集 $R_1,R_2$ 放回到独立集。注意,在问这些边的同时,上一步合并成的独立集此时也会进行下一轮合并,产生新的独立集序列,$R_1,R_2$ 放回的是这个独立集序列。
因此,存在 $\mathcal O(\log_kn)$ 轮询问,$\mathcal O(nk\log_k n)$ 步移动的算法,其中 $k$ 可以取任意值。
人类勇气之赞歌
idea, std, data by GeZhiyuan, solution by GeZhiyuan, zhoukangyang
首先不难有一个动态规划,用 $f_i$ 表示 $[1, i]$ 的答案。直接做就是 $O(n^2k)$ 的。
接下来用一些手段去优化转移,考虑从 $1$ 到 $n$ 扫 $r$,同步维护 $s_{u, l}$ 表示 $[l, r]$ 区间的第 $u$ 大。
考虑某一时刻如果有 $s_{u, l} = s_{u, l+1}$,那么后续过程中两者保持相等。考虑扫描过程中,如果出现了 $s_{u, l} = s_{u, l+1}$,就将两个直接合并成一段。然后暴力修改有更改的 $s_{u,l}$(对于合并过的连续段快速跳掉)。
可以证明这样暴力修改只会进行 $O(nk^2)$ 次:
考虑将 $a_r$ 加入时,对于某个 $l$,若存在 $s_{u, l} = a_r$ 则 $p_l = u$,否则 $p_l = k+1$。
且如果 $s_{u, l} = s_{u, l-1}$,则 $\forall v \in [1, u]$,都有 $s_{v, l} = s_{v, l+1}$。记 $h_l$ 表示最大的满足 $s_{u, l} = s_{u, l+1}$ 的 $u$,不难发现 $h_l$ 在扫描过程中不会减小。
- 不难发现有 $p_{l+1} \leq p_l \leq p_{l+1}+1$,因此 $a_r$ 对 $s_{u, l}$ 直接的修改只有 $k$ 段。
- 但考虑有些 $s_{u, l}$ 是继承了 $s_{u-1, l}$ 的值,由于我们快速跳过了值域相同的连续段,因此实际上只要考虑 $s_{u, l} \neq s_{u, l+1}$ 的位置即可:
- 如果 $p_l \neq p_{l+1}$,这样的位置只有 $k-1$ 个,每个位置只要维护 $k$ 个信息,因此单次修改这样的位置修改不超 $k^2$ 个。
- 如果 $p_l = p_{l+1}$,不难发现此时 $h_l$ 会增加 $1$,因此均摊总共只会对 $nk$ 个这样的位置进行修改,每个位置要维护 $k$ 个信息,因此总共也不会超出 $nk^2$ 次。
同理用 $t_{u, l}$ 表示 $[l, r]$ 的第 $u$ 小。至此我们知道了有效的区间修改只有 $O(nk^2)$ 次,接下来我们要尝试做到 $O(1)$ 的修改,这部分大家可能都知道该怎么做但比较 $\text{dirty work}$,需要选手有很大的勇气。
对于所有 $1 \leq u < k$,考虑将 $s_{u}$ 和 $t_{k-u}$ 这两个数组一起维护对答案的贡献;考虑进一步分析性质发现每一次修改都是一个后缀,用如下手段维护:
- 我们考虑用某种手段将下标划分成若干连续段,每段内用凸包单独维护,每段的凸包根据情况分为如下三种,假设其对应下标是 $[l, r]$:
- 如果 $s_{u, l} = s_{u, l+1} = \dots = s_{u, r}$,则考虑称其为 A类,此时我们考虑对 $t$ 用凸包进行维护,对于每个 $t_{u, i} \neq t_{u, i+1}$ 的点,向凸包内插入 $(x - t_{u, i})^2 + f_{i-1}$,进一步发现实际上比较两个值的时候,$x^2$ 上的系数是相同的,因此实际上等价于插入直线。
- 如果 $t_{k-u, l} = t_{l-u, l+1}=\dots=t_{l-u, r}$,则考虑称其为 B类,此时同理对 $s$ 用凸包进行维护。
- 如果同时有 $s_{u, l} = s_{u, l+1} = \dots = s_{u, r}$ 和 $t_{k-u, l} = t_{l-u, l+1}=\dots=t_{l-u, r}$,那么称之为 C 类。这种直接可以快速修改和统计答案。
- 根据 “某一时刻如果有 $s_{u, l} = s_{u, l+1}$,那么后续过程中两者保持相等”,如果对 A类 直接进行修改,其只可能要么继续保持 A类,要么变成 C类,对于 B类 和 C类 是类似的的,如果两个下标形成了一段,那么他们永远都可以在同一段。
- 考虑我们再尝试将连续段进行合并,如果有两个相邻的连续段可以合并成 A, B, C 类其中之一,那么我就强制让他们合并到一起。
- 这样可以证明,一个 $s$ 或 $t$ 相同的区间只会最多影响三个连续段。于是均摊下来每次可以暴力找出所有影响到的连续段。
- 然后由于修改又是后缀,因此我们可以把后缀的影响到的连续段先全部取出来,将修改作用于上面后依次尝试和前面合并即可。
- 由于 $r$ 增大时,许多东西的变化都是单调变优的,因此我们考虑如下维护过程:
- 如果我们要修改某一个连续段,我们假设这个连续段是 A类 的,对于 B类 是对称的,而 C类 修改是容易的:
- 如果我们是对 $s_u$ 进行修改,那么由于我们维护好了 $t$ 的凸包,且 $s_{u, l}$ 的变化一定也是单调的,因此只需要维护一个指针在凸包上暴力移动均摊就是对的。
- 否则考虑必定是 $t_{k-u}$ 在这个区间上的一个后缀被修改,我们将这些直线直接插入凸包中不好插入,因为斜率不一定单调,可能被包含在当前凸包的斜率中,但根据 $t$ 的单调性和修改的单调性,你发现可以将其中一侧的直线直接全部从凸包中删除,因为这些线段是原本被修改的位置贡献的,新的一定更优。至此我们将那一侧的直线全部删除后正常维护凸包即可,均摊也是对的。
- 而合并两个连续段呢?首先 C类 间的合并好做,如果 A类 和 C类 合并则可以认为先将 C类 转为 A类,而 A类 和 B类 没法合并。因此我们只需要想清楚 A类 和 A类 怎么合并即可,B类 和 B类 的合并是同理的:
- 考虑到 $t_{k, u}$ 是单调的,因此我们合并两个连续段时,凸包的斜率不交(实际上至多有一个相同,但可以将较劣的直接弹掉),因此直接凸包合并即可。但发现这里需要支持 $O(1)$ 把两个序列拼起来,因此实际上凸包需要用链表维护顺序。
- 如果我们要修改某一个连续段,我们假设这个连续段是 A类 的,对于 B类 是对称的,而 C类 修改是容易的:
- 考虑维护对答案的贡献异常好算,答案是单调的,因此只需要每次发生修改时,把新的结果直接贡献到答案即可。
可能说的不是很清楚,因为确实细节太多!但至此我们实现了修改均摊 $O(1)$,时间复杂度 $O(nk^2)$,空间复杂度 $O(nk)$。




 ,所以在子任务 3 中对 $n$ 较小时放宽了比值要求。
,所以在子任务 3 中对 $n$ 较小时放宽了比值要求。
 鄂公网安备 42010202000505 号
鄂公网安备 42010202000505 号